Need Help?
Ryukoku Extension Center
龍谷エクステンションセンター(REC)シーズダイジェスト

[プロフィール]
大阪大学大学院理学研究科数学専攻修士課程修了。博士( 理学)。専門分野は知能情報学、研究テーマはデータマイニング、機械学習。NTTコミュニケーション科学基礎研究所を経て平成17年より現職。

ネットワーク情報空間内で爆発的に増大する多様で膨大なデータから、どのように必要な情報や有用な知識を抽出するかという“データマイニング”の研究が注目され、データに潜む概念やメカニズムを抽出する機械学習が、有力な解決アプローチとして期待されています。
本研究室では、統計的機械学習理論と複雑系ネットワーク科学の観点から、現象の数理モデリングと数理解析、学習の数理理論、実データの統計分析、データマイニングなどについて研究を行っています。

新たなマーケティングにつながる情報拡散モデル
昔はテレビや新聞が情報を発信して、私たちはそれを受け取る側でしたが、近年、ソーシャルメディアでたくさんの人が情報を発信したり、コミュニケーションしたりするようになりました。その中で、ネットワーク内に蓄積されている膨大なデータ、いわゆるビッグデータをどう解析してどう活用していくかが課題になっています。
それを解決するためのアプローチとして期待されているのが機械学習です。機械学習は人工知能研究の一分野で、人間が自然に行っている学習能力と同様の機能をコンピュータで実現し、この技術を使ってビッグデータに埋没している知識などを発見しようという研究が進められています。
例えばブログなら、読者やファンになってつながっていくことで、大規模なソーシャルネットワークができあがっています。ツィッターでおもしろい情報を発信すると、フォローしている人のところに情報が届き、さらにその人をフォローしている人のところに情報が伝わって拡散していきます。
ソーシャルネットワークは情報を拡散する重要な媒体で、ある一言がワッと広がって、情報が拡散することがあります。昔ながらのマーケティングは、テレビの有名なコンテンツに広告を出すというものですが、それに対して、ソーシャルネットワークを活用した「バイラルマーケティング」は、世界中の何人かの人に最初に情報を持ってもらい、その人たちからどんどんクチコミで情報を広げていくという手法です。
最初に情報を渡す人をどう選ぶかが問題で、ソーシャルネットワークの中のだれとだれに情報を渡せば、最も効果的に情報を拡散することができるかに、世界中のさまざまな研究者が取り組んでいます。
共同研究で行った「情報拡散モデルに基づく社会ネットワーク上の影響度分析」では、ある情報を持った人がその情報をほかの人に伝えるかどうか、伝える、伝えないの確率に基づく情報拡散モデルを考えました。
一番のポイントはできるだけ早く答えを求めるということで、私たちのグループは、通常の方法より3桁速い方法、つまり従来法では1000日かかるところを1日で近似解を求める方法を研究しました。
ソーシャルネットワークの今後の広がりを予測
ソーシャルネットワークが将来どう広がっていくかを予測するため、信頼ネットワークの進化の分析も行っています。
ネットワーク上でいろいろな人がレビューを書いていますが、良いことを書いていたらその人への信頼度があがります。信頼のネットワークがどう広がるかを調べるため、私たちは媒介者に着目しました。
媒介者は単にリンク関係において2人を媒介するだけでなく、ちゃんとアクティビティーにおいても、3人が同じ分野で”共起”するということが、信頼リンクを結ぶ原因ではないかということを数理モデルを使って調べています。
こういう分野に興味をもってレビューを書く人が、こういう分野に対して評価をもらう人に、信頼リンクを生成しやすいということが分析できます。
例えばテレビゲームとかSF映画を好んでレビューする人は、SFファンタジーとかでレビューしたらいつも信頼を獲得する人、こういう人との間に信頼関係ができやすいことがわかりました。
ここ半年から1年くらいの様子を見て、これから3カ月くらいに信頼ネットワークがどうなるか、従来の方法より精度をあげた予測ができるような研究を行っています。
ソーシャルネットワーク上での情報拡散
Web空間内にさまざまな大規模ソーシャルネットワークが形成され、多様な情報の拡散を媒介、イノベーションの普及、噂の拡散、大衆による大規模な社会運動などが起こっている。

影響最大化問題
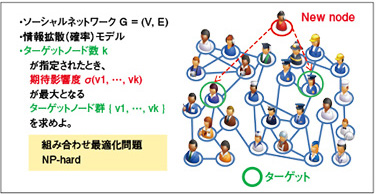
最も効果的に情報を拡散するには、ソーシャルネットワークの中のだれとだれに情報を渡せばいいかという、影響最大化問題の研究に多くの研究者が取り組んでいる。
人の行動を分析し、新たな知識を発見する
Flickrなどの画像共有サイトにはたくさんの画像データが蓄積されていて、それにはジオタグが付いているのでいつどこで撮ったかがわかります。日本で撮った写真を集めてどこで撮影されたかプロットしてみると、「ここはこの時期が旬」というスポットの旬を抽出することができます。
そこで、各スポットにどんなシーズンがあり、短い期間にどのくらいたくさん人が訪れるかという旬の度合いはどれほどか、年間訪問者数はどれほどかといった情報を、同時に可視化する方法を提案しました。
また、料理レシピサイトに投稿した料理に対して、たくさんの人がポジティブメッセージを送るかどうか、その料理が流行るか流行らないかがわかります。
レシピの文章から、例えば「大根」が何回出ているか、「ひっくり返す」が何回出ているかという具合に、食材と調味料と調理法に関する単語の頻度を抽出して、数式を作って予測します。性能評価すると、当りやすいレシピと当りにくいレシピがあるなど、まだ課題は残りますが、これらのことばの組み合わせパターンが出たら、この人がポジティブメッセージを送るということが高い確率で予測できます。
このように、ソーシャルメディアから人の行動を見つけて分析し、知識を発見するといったことも、研究の対象にしています。
集合知に基づく観光案内システムの高度化
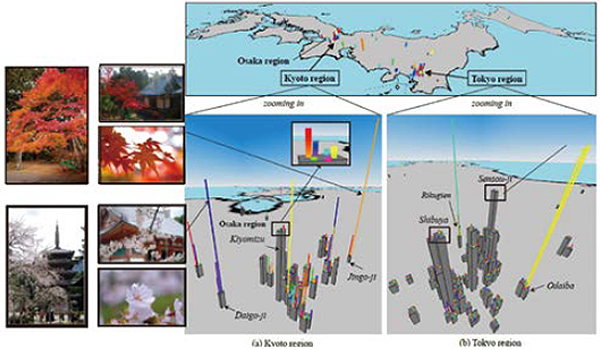
写真共有サイトの画像のジオタグから人気スポットを抽出、各スポットのシーズンとシーズンの魅力度=バースト度、年間の訪問者数などを分析して、人気観光スポットを効果的に比較・分析できる新たな可視化法を提案したもの。
研究者からのメッセージ
複雑な情報を数理的に整理して知識として見せる
たとえば観光スポットについて、みんながどこに行って何をしてるかを分析することで、みんなの意見を反映した知識を提供することができます。ネットの中で起こっている複雑なことをうまく整理して、実はこうだという知識として見せる方法を作りたいと思っています。
対象になっているテーマはソフトな内容ですが、その手法はきちんとした数学的、科学的なもので、数学や物理の伝統を踏襲してやっています。基本的には、定義から定理という流れで数学的に厳密に書いており、おもしろ味は少ないかもしれませんが、絶対正しいことを導き出しています。とはいえ現実には、数学的に厳密にできないことが多いのですが、数理的にできる範囲内でトライしていきたいと思っています。